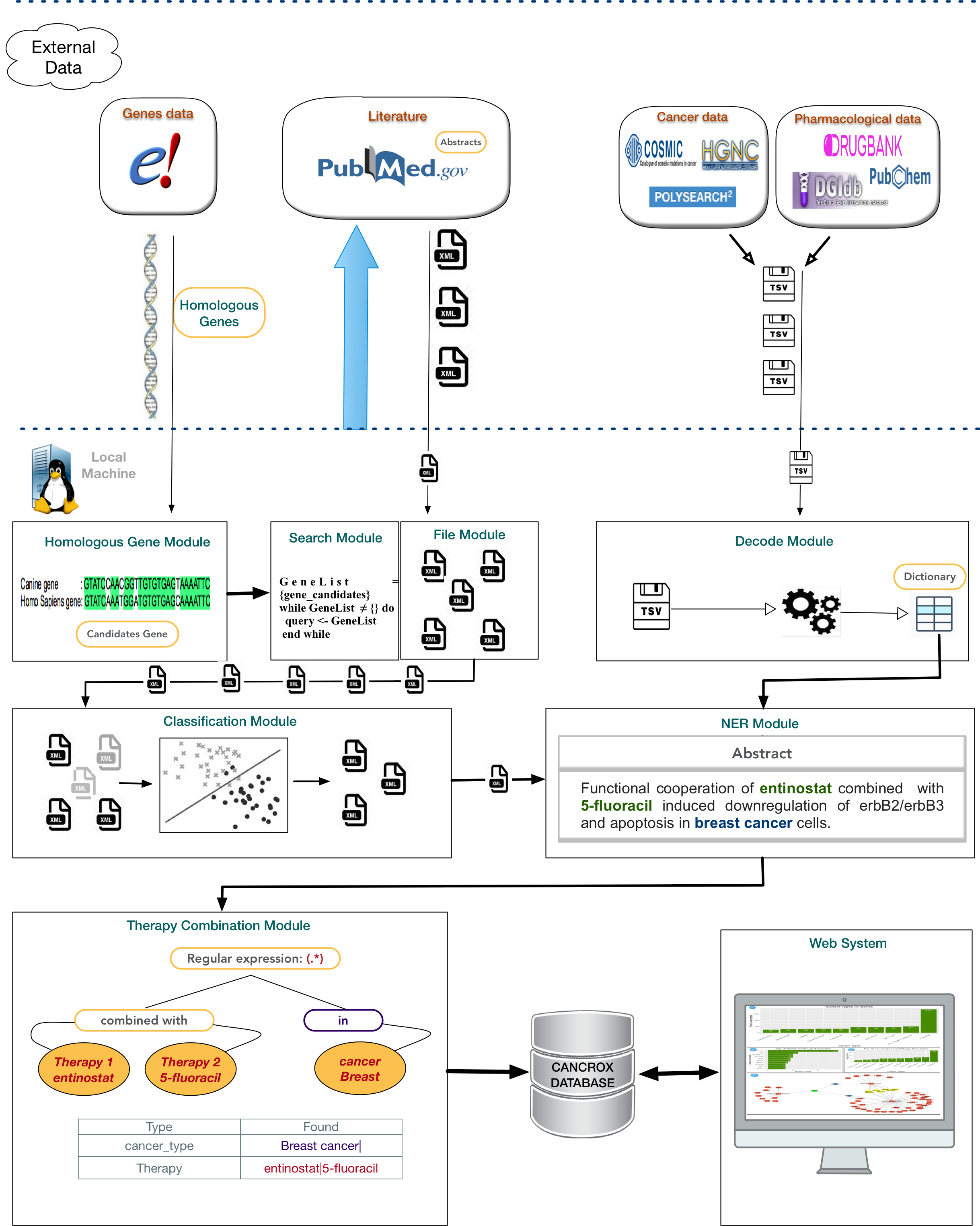
The CANCROX tool is able to perform TM and NLP analysis in thousands and even millions of scientific articles, constructing a reference database of similar genes between humans and dogs associated with cancer, hereinafter referred to as candidate genes. In addition to candidate genes, the types of cancer associated with these genes, therapies, and drugs and their different combinations are identified and stored in this database.
Architecture of the CANCROX database. The pipeline starts with the download of external databases and pre-processing, which consists of organizing the different data patterns in structured database tables. Next, the pre-processed data are sent to the learning algorithms of the machine (where articles are classified as 'positive results' and 'negative results') and articles with 'positive results' are submitted to the NER module (Named Entity Recognition), where therapies, drugs and types of cancer are recognized. In the final step of this processing phase, the combination of therapies is identified. The first tier of the tool grants access to external databases to obtain information about genes, drugs, and scientific texts. Processing and persistence of the data occur in the second tier. The third tier is responsible for providing mechanisms of data access, i.e., permitting visualization of the processed data.